import pandas as pdData Transformation
Introduction
It’s very rare that data arrive in exactly the right form you need. Often, you’ll need to create some new variables or summaries, or maybe you just want to rename the variables or reorder the observations to make the data a little easier to work with.
You’ll learn how to do all that (and more!) in this chapter, which will introduce you to data transformation using the pandas package and a new dataset on flights that departed New York City in 2013.
The goal of this chapter is to give you an overview of all the key tools for transforming a data frame, a special kind of object that holds tabular data.
We’ll come back these functions in more detail in later chapters, as we start to dig into specific types of data (e.g. numbers, strings, dates).
Prerequisites
In this chapter we’ll focus on the pandas package, one of the most widely used tools for data science. You’ll need to ensure you have pandas installed. To do this, you can run
If this command fails, you don’t have pandas installed. Open up the terminal in Visual Studio Code (Terminal -> New Terminal), cd to the folder you are working in, and type in uv add pandas.
Furthermore, if you wish to check which version of pandas you’re using, it’s
pd.__version__'2.2.3'You’ll also need the data. Most of the time, data will need to be loaded from a file or the internet. These data are no different, but one of the amazing things about pandas is how many different types of data it can load, including from files on the internet.
The data is around 50MB in size so you will need a good internet connection or a little patience for it to download.
Let’s download the data:
url = "https://raw.githubusercontent.com/byuidatascience/data4python4ds/master/data-raw/flights/flights.csv"
flights = pd.read_csv(url)If the above code worked, then you’ve downloaded the data in CSV format and put it in a data frame. Let’s look at the first few rows using the .head() function that works on all pandas data frames.
flights.head()| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01T10:00:00Z |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01T10:00:00Z |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01T10:00:00Z |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01T10:00:00Z |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01T11:00:00Z |
To get more general information on the columns, the data types (dtypes) of the columns, and the size of the dataset, use .info().
flights.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 336776 entries, 0 to 336775
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 336776 non-null int64
1 month 336776 non-null int64
2 day 336776 non-null int64
3 dep_time 328521 non-null float64
4 sched_dep_time 336776 non-null int64
5 dep_delay 328521 non-null float64
6 arr_time 328063 non-null float64
7 sched_arr_time 336776 non-null int64
8 arr_delay 327346 non-null float64
9 carrier 336776 non-null object
10 flight 336776 non-null int64
11 tailnum 334264 non-null object
12 origin 336776 non-null object
13 dest 336776 non-null object
14 air_time 327346 non-null float64
15 distance 336776 non-null int64
16 hour 336776 non-null int64
17 minute 336776 non-null int64
18 time_hour 336776 non-null object
dtypes: float64(5), int64(9), object(5)
memory usage: 48.8+ MBYou might have noticed the short abbreviations that appear in the Dtypes column. These tell you the type of the values in their respective columns: int64 is short for integer (eg whole numbers) and float64 is short for double-precision floating point number (these are real numbers). object is a bit of a catch all category for any data type that pandas is not really confident about inferring. Although not found here, other data types include string for text and datetime for combinations of a date and time.
The table below gives some of the most common data types you are likely to encounter.
| Name of data type | Type of data |
|---|---|
| float64 | real numbers |
| category | categories |
| datetime64 | date times |
| int64 | integers |
| bool | True or False |
| string | text |
The different column data types are important because the operations you can perform on a column depend so much on its “type”; for example, you can remove all punctuation from strings while you can multiply ints and floats.
We would like to work with the "time_hour" variable in the form of a datetime; fortunately, pandas makes it easy to perform that conversion on that specific column
flights["time_hour"]0 2013-01-01T10:00:00Z
1 2013-01-01T10:00:00Z
2 2013-01-01T10:00:00Z
3 2013-01-01T10:00:00Z
4 2013-01-01T11:00:00Z
...
336771 2013-09-30T18:00:00Z
336772 2013-10-01T02:00:00Z
336773 2013-09-30T16:00:00Z
336774 2013-09-30T15:00:00Z
336775 2013-09-30T12:00:00Z
Name: time_hour, Length: 336776, dtype: objectflights["time_hour"] = pd.to_datetime(flights["time_hour"], format="%Y-%m-%dT%H:%M:%SZ")pandas basics
pandas is a really comprehensive package, and this book will barely scratch the surface of what it can do. But it’s built around a few simple ideas that, once they’ve clicked, make life a lot easier.
Let’s start with the absolute basics. The most basic pandas object is DataFrame. A DataFrame is a 2-dimensional data structure that can store data of different types (including characters, integers, floating point values, categorical data, even lists) in columns. It is made up of rows and columns (with each row-column cell containing a value), plus two bits of contextual information: the index (which carries information about each row) and the column names (which carry information about each column).

Perhaps the most important notion to have about pandas data frames is that they are built around an index that sits on the left-hand side of the data frame. Every time you perform an operation on a data frame, you need to think about how it might or might not affect the index; or, put another way, whether you want to modify the index.
Let’s see a simple example of this with a made-up data frame:
df = pd.DataFrame(
data={
"col0": [0, 0, 0, 0],
"col1": [0, 0, 0, 0],
"col2": [0, 0, 0, 0],
"col3": ["a", "b", "b", "a"],
"col4": ["alpha", "gamma", "gamma", "gamma"],
},
index=["row" + str(i) for i in range(4)],
)
df.head()| col0 | col1 | col2 | col3 | col4 | |
|---|---|---|---|---|---|
| row0 | 0 | 0 | 0 | a | alpha |
| row1 | 0 | 0 | 0 | b | gamma |
| row2 | 0 | 0 | 0 | b | gamma |
| row3 | 0 | 0 | 0 | a | gamma |
You can see there are 5 columns (named "col0" to "col4") and that the index consists of four entries named "row0" to "row3".
A second key point you should know is that the operations on a pandas data frame can be chained together. We need not perform one assignment per line of code; we can actually do multiple assignments in a single command.
Let’s see an example of this. We’re going to string together four operations:
- we will use
query()to find only the rows where the destination"dest"column has the value"IAH". This doesn’t change the index, it only removes irrelevant rows. In effect, this step removes rows we’re not interested in. - we will use
groupby()to group rows by the year, month, and day (we pass a list of columns to thegroupby()function). This step changes the index; the new index will have three columns in that track the year, month, and day. In effect, this step changes the index. - we will choose which columns we wish to keep after the
groupby()operation by passing a list of them to a set of square brackets (the double brackets are because it’s a list within a data frame). Here we just want one column,"arr_delay". This doesn’t affect the index. In effect, this step removes columns we’re not interested in. - finally, we must specify what
groupby()operation we wish to apply; when aggregating the information in multiple rows down to one row, we need to say how that information should be aggregated. In this case, we’ll use themean(). In effect, this step applies a statistic to the variable(s) we selected earlier, across the groups we created earlier.
(flights.query("dest == 'IAH'").groupby(["year", "month", "day"])[["arr_delay"]].mean())| arr_delay | |||
|---|---|---|---|
| year | month | day | |
| 2013 | 1 | 1 | 17.850000 |
| 2 | 7.000000 | ||
| 3 | 18.315789 | ||
| 4 | -3.200000 | ||
| 5 | 20.230769 | ||
| ... | ... | ... | |
| 12 | 27 | 6.166667 | |
| 28 | 9.500000 | ||
| 29 | 23.611111 | ||
| 30 | 23.684211 | ||
| 31 | -4.933333 |
365 rows × 1 columns
You can see here that we’ve created a new data frame with a new index. To do it, we used four key operations:
- manipulating rows
- manipulating the index
- manipulating columns
- applying statistics
Most operations you could want to do to a single data frame are covered by these, but there are different options for each of them depending on what you need.
Let’s now dig a bit more into these operations.
Manipulating Rows in Data Frames
Let’s create some fake data to show how this works.
import numpy as np
df = pd.DataFrame(
data=np.reshape(range(36), (6, 6)),
index=["a", "b", "c", "d", "e", "f"],
columns=["col" + str(i) for i in range(6)],
dtype=float,
)
df["col6"] = ["apple", "orange", "pineapple", "mango", "kiwi", "lemon"]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon |
Accessing Rows
To access a particular row directly, you can use df.loc['rowname'] or df.loc[['rowname1', 'rowname2']] for two different rows.
For example,
df.loc[["a", "b"]]| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange |
But you can also access particular rows based on their location in the data frame using .iloc. Remember that Python indices begin from zero, so to retrieve the first row you would use .iloc[0]:
df.iloc[0]col0 0.0
col1 1.0
col2 2.0
col3 3.0
col4 4.0
col5 5.0
col6 apple
Name: a, dtype: objectThis works for multiple rows too. Let’s grab the first and third rows (in positions 0 and 2) by passing a list of positions:
df.iloc[[0, 2]]| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
There are other ways to access multiple rows that make use of slicing but we’ll leave that topic for another time.
Filtering rows with query
As with the flights example, we can also filter rows based on a condition using query():
df.query("col6 == 'kiwi' or col6 == 'pineapple'")| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi |
For numbers, you can also use the greater than and less than signs:
df.query("col0 > 6")| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon |
In fact, there are lots of options that work with query(): as well as > (greater than), you can use >= (greater than or equal to), < (less than), <= (less than or equal to), == (equal to), and != (not equal to). You can also use the commands and as well as or to combine multiple conditions. Here’s an example of and from the flights data frame:
# Flights that departed on January 1
flights.query("month == 1 and day == 1")| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 10:00:00 |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 10:00:00 |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01 10:00:00 |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01 10:00:00 |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01 11:00:00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 837 | 2013 | 1 | 1 | 2356.0 | 2359 | -3.0 | 425.0 | 437 | -12.0 | B6 | 727 | N588JB | JFK | BQN | 186.0 | 1576 | 23 | 59 | 2013-01-02 04:00:00 |
| 838 | 2013 | 1 | 1 | NaN | 1630 | NaN | NaN | 1815 | NaN | EV | 4308 | N18120 | EWR | RDU | NaN | 416 | 16 | 30 | 2013-01-01 21:00:00 |
| 839 | 2013 | 1 | 1 | NaN | 1935 | NaN | NaN | 2240 | NaN | AA | 791 | N3EHAA | LGA | DFW | NaN | 1389 | 19 | 35 | 2013-01-02 00:00:00 |
| 840 | 2013 | 1 | 1 | NaN | 1500 | NaN | NaN | 1825 | NaN | AA | 1925 | N3EVAA | LGA | MIA | NaN | 1096 | 15 | 0 | 2013-01-01 20:00:00 |
| 841 | 2013 | 1 | 1 | NaN | 600 | NaN | NaN | 901 | NaN | B6 | 125 | N618JB | JFK | FLL | NaN | 1069 | 6 | 0 | 2013-01-01 11:00:00 |
842 rows × 19 columns
Note that equality is tested by == and not by =, because the latter is used for assignment.
Re-arranging Rows
Again and again, you will want to re-order the rows of your data frame according to the values in a particular column. pandas makes this very easy via the .sort_values() function. It takes a data frame and a set of column names to sort by. If you provide more than one column name, each additional column will be used to break ties in the values of preceding columns. For example, the following code sorts by the departure time, which is spread over four columns.
flights.sort_values(["year", "month", "day", "dep_time"])| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 10:00:00 |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 10:00:00 |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01 10:00:00 |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01 10:00:00 |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01 11:00:00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 111291 | 2013 | 12 | 31 | NaN | 705 | NaN | NaN | 931 | NaN | UA | 1729 | NaN | EWR | DEN | NaN | 1605 | 7 | 5 | 2013-12-31 12:00:00 |
| 111292 | 2013 | 12 | 31 | NaN | 825 | NaN | NaN | 1029 | NaN | US | 1831 | NaN | JFK | CLT | NaN | 541 | 8 | 25 | 2013-12-31 13:00:00 |
| 111293 | 2013 | 12 | 31 | NaN | 1615 | NaN | NaN | 1800 | NaN | MQ | 3301 | N844MQ | LGA | RDU | NaN | 431 | 16 | 15 | 2013-12-31 21:00:00 |
| 111294 | 2013 | 12 | 31 | NaN | 600 | NaN | NaN | 735 | NaN | UA | 219 | NaN | EWR | ORD | NaN | 719 | 6 | 0 | 2013-12-31 11:00:00 |
| 111295 | 2013 | 12 | 31 | NaN | 830 | NaN | NaN | 1154 | NaN | UA | 443 | NaN | JFK | LAX | NaN | 2475 | 8 | 30 | 2013-12-31 13:00:00 |
336776 rows × 19 columns
You can use the keyword argument ascending=False to re-order by a column or columns in descending order. For example, this code shows the most delayed flights:
flights.sort_values("dep_delay", ascending=False)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7072 | 2013 | 1 | 9 | 641.0 | 900 | 1301.0 | 1242.0 | 1530 | 1272.0 | HA | 51 | N384HA | JFK | HNL | 640.0 | 4983 | 9 | 0 | 2013-01-09 14:00:00 |
| 235778 | 2013 | 6 | 15 | 1432.0 | 1935 | 1137.0 | 1607.0 | 2120 | 1127.0 | MQ | 3535 | N504MQ | JFK | CMH | 74.0 | 483 | 19 | 35 | 2013-06-15 23:00:00 |
| 8239 | 2013 | 1 | 10 | 1121.0 | 1635 | 1126.0 | 1239.0 | 1810 | 1109.0 | MQ | 3695 | N517MQ | EWR | ORD | 111.0 | 719 | 16 | 35 | 2013-01-10 21:00:00 |
| 327043 | 2013 | 9 | 20 | 1139.0 | 1845 | 1014.0 | 1457.0 | 2210 | 1007.0 | AA | 177 | N338AA | JFK | SFO | 354.0 | 2586 | 18 | 45 | 2013-09-20 22:00:00 |
| 270376 | 2013 | 7 | 22 | 845.0 | 1600 | 1005.0 | 1044.0 | 1815 | 989.0 | MQ | 3075 | N665MQ | JFK | CVG | 96.0 | 589 | 16 | 0 | 2013-07-22 20:00:00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336771 | 2013 | 9 | 30 | NaN | 1455 | NaN | NaN | 1634 | NaN | 9E | 3393 | NaN | JFK | DCA | NaN | 213 | 14 | 55 | 2013-09-30 18:00:00 |
| 336772 | 2013 | 9 | 30 | NaN | 2200 | NaN | NaN | 2312 | NaN | 9E | 3525 | NaN | LGA | SYR | NaN | 198 | 22 | 0 | 2013-10-01 02:00:00 |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | 3461 | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 | 2013-09-30 16:00:00 |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | 3572 | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 | 2013-09-30 15:00:00 |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | 3531 | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 | 2013-09-30 12:00:00 |
336776 rows × 19 columns
You can of course combine all of the above row manipulations to solve more complex problems. For example, we could look for the top three destinations of the flights that were most delayed on arrival that left on roughly on time:
(
flights.query("dep_delay <= 10 and dep_delay >= -10")
.sort_values("arr_delay", ascending=False)
.iloc[[0, 1, 2]]
)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 55985 | 2013 | 11 | 1 | 658.0 | 700 | -2.0 | 1329.0 | 1015 | 194.0 | VX | 399 | N629VA | JFK | LAX | 336.0 | 2475 | 7 | 0 | 2013-11-01 11:00:00 |
| 181270 | 2013 | 4 | 18 | 558.0 | 600 | -2.0 | 1149.0 | 850 | 179.0 | AA | 707 | N3EXAA | LGA | DFW | 234.0 | 1389 | 6 | 0 | 2013-04-18 10:00:00 |
| 256340 | 2013 | 7 | 7 | 1659.0 | 1700 | -1.0 | 2050.0 | 1823 | 147.0 | US | 2183 | N948UW | LGA | DCA | 64.0 | 214 | 17 | 0 | 2013-07-07 21:00:00 |
Exercises
Find all flights that
Had an arrival delay of two or more hours
Flew to Houston (
"IAH"or"HOU")Were operated by United, American, or Delta
Departed in summer (July, August, and September)
Arrived more than two hours late, but didn’t leave late
Were delayed by at least an hour, but made up over 30 minutes in flight
Sort
flightsto find the flights with longest departure delays.Sort
flightsto find the fastest flightsWhich flights traveled the farthest?
Does it matter what order you used
query()andsort_values()in if you’re using both? Why/why not? Think about the results and how much work the functions would have to do.
Manipulating Columns
This section will show you how to apply various operations you may need to columns in your data frame.
Note
Some pandas operations can apply either to columns or rows, depending on the syntax used. For example, accessing values by position can be achieved in the same way for rows and columns via .iloc where to access the ith row you would use df.iloc[i] and to access the jth column you would use df.iloc[:, j] where : stands in for ‘any row’.
Creating New Columns
Let’s now move on to creating new columns, either using new information or from existing columns. Given a data frame, df, creating a new column with the same value repeated is as easy as using square brackets with a string (text enclosed by quotation marks) in.
df["new_column0"] = 5
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | |
|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 5 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 5 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 5 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 5 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 5 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 |
If we do the same operation again, but with a different right-hand side, it will overwrite what was already in that column. Let’s see this with an example where we put different values in each position by assigning a list to the new column.
df["new_column0"] = [0, 1, 2, 3, 4, 5]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | |
|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 |
Exercise
What happens if you try to use assignment where the right-hand side values are longer or shorter than the length of the data frame?
By passing a list within the square brackets, we can actually create more than one new column:
df[["new_column1", "new_column2"]] = [5, 6]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | new_column1 | new_column2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 |
Very often, you will want to create a new column that is the result of an operation on existing columns. There are a couple of ways to do this. The ‘stand-alone’ method works in a similar way to what we’ve just seen except that we refer to the data frame on the right-hand side of the assignment statement too:
df["new_column3"] = df["col0"] - df["new_column0"]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | new_column1 | new_column2 | new_column3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 | 0.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 | 5.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 | 10.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 | 15.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 | 20.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 | 25.0 |
The other way to do this involves an ‘assign()’ statement and is used when you wish to chain multiple steps together (like we saw earlier). These use a special syntax called a ‘lambda’ statement, which (here at least) just provides a way of specifying to pandas that we wish to perform the operation on every row. Below is an example using the flights data. You should note though that the word ‘row’ below is a dummy; you could replace it with any variable name (for example, x) but row makes what is happening a little bit clearer.
(
flights.assign(
gain=lambda row: row["dep_delay"] - row["arr_delay"],
speed=lambda row: row["distance"] / row["air_time"] * 60,
)
)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | ... | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | gain | speed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | ... | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 10:00:00 | -9.0 | 370.044053 |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | ... | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 10:00:00 | -16.0 | 374.273128 |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | ... | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01 10:00:00 | -31.0 | 408.375000 |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | ... | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01 10:00:00 | 17.0 | 516.721311 |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | ... | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01 11:00:00 | 19.0 | 394.137931 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336771 | 2013 | 9 | 30 | NaN | 1455 | NaN | NaN | 1634 | NaN | 9E | ... | NaN | JFK | DCA | NaN | 213 | 14 | 55 | 2013-09-30 18:00:00 | NaN | NaN |
| 336772 | 2013 | 9 | 30 | NaN | 2200 | NaN | NaN | 2312 | NaN | 9E | ... | NaN | LGA | SYR | NaN | 198 | 22 | 0 | 2013-10-01 02:00:00 | NaN | NaN |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | ... | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 | 2013-09-30 16:00:00 | NaN | NaN |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | ... | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 | 2013-09-30 15:00:00 | NaN | NaN |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | ... | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 | 2013-09-30 12:00:00 | NaN | NaN |
336776 rows × 21 columns
Note
A lambda function is like any normal function in Python except that it has no name, and it tends to be contained in one line of code. A lambda function is made of an argument, a colon, and an expression, like the following lambda function that multiplies an input by three.
lambda x: x*3Accessing Columns
Just as with selecting rows, there are many options and ways to select the columns to operate on. The one with the simplest syntax is the name of the data frame followed by square brackets and the column name (as a string)
df["col0"]a 0.0
b 6.0
c 12.0
d 18.0
e 24.0
f 30.0
Name: col0, dtype: float64If you need to select multiple columns, you cannot just pass a string into df[...]; instead you need to pass an object that is iterable (and so have multiple items). The most straight forward way to select multiple columns is to pass a list. Remember, lists comes in square brackets so we’re going to see something with repeated square brackets: one for accessing the data frame’s innards and one for the list.
df[["col0", "new_column0", "col2"]]| col0 | new_column0 | col2 | |
|---|---|---|---|
| a | 0.0 | 0 | 2.0 |
| b | 6.0 | 1 | 8.0 |
| c | 12.0 | 2 | 14.0 |
| d | 18.0 | 3 | 20.0 |
| e | 24.0 | 4 | 26.0 |
| f | 30.0 | 5 | 32.0 |
If you want to access particular rows at the same time, use the .loc access function:
df.loc[["a", "b"], ["col0", "new_column0", "col2"]]| col0 | new_column0 | col2 | |
|---|---|---|---|
| a | 0.0 | 0 | 2.0 |
| b | 6.0 | 1 | 8.0 |
And, just as with rows, we can access columns by their position using .iloc (where : stands in for ‘any row’).
df.iloc[:, [0, 1]]| col0 | col1 | |
|---|---|---|
| a | 0.0 | 1.0 |
| b | 6.0 | 7.0 |
| c | 12.0 | 13.0 |
| d | 18.0 | 19.0 |
| e | 24.0 | 25.0 |
| f | 30.0 | 31.0 |
There are other ways to access multiple columns that make use of slicing but we’ll leave that topic for another time.
Sometimes, you’ll want to select columns based on the type of data that they hold. For this, pandas provides a function .select_dtypes(). Let’s use this to select all columns with integers in the flights data.
flights.select_dtypes("int")| year | month | day | sched_dep_time | sched_arr_time | flight | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 515 | 819 | 1545 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 529 | 830 | 1714 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 540 | 850 | 1141 | 1089 | 5 | 40 |
| 3 | 2013 | 1 | 1 | 545 | 1022 | 725 | 1576 | 5 | 45 |
| 4 | 2013 | 1 | 1 | 600 | 837 | 461 | 762 | 6 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336771 | 2013 | 9 | 30 | 1455 | 1634 | 3393 | 213 | 14 | 55 |
| 336772 | 2013 | 9 | 30 | 2200 | 2312 | 3525 | 198 | 22 | 0 |
| 336773 | 2013 | 9 | 30 | 1210 | 1330 | 3461 | 764 | 12 | 10 |
| 336774 | 2013 | 9 | 30 | 1159 | 1344 | 3572 | 419 | 11 | 59 |
| 336775 | 2013 | 9 | 30 | 840 | 1020 | 3531 | 431 | 8 | 40 |
336776 rows × 9 columns
There are other occasions when you’d like to select columns based on criteria such as patterns in the name of the column. Because Python has very good support for text, this is very possible but doesn’t tend to be so built-in to pandas functions. The trick is to generate a list of column names that you want from the pattern you’re interested in.
Let’s see a couple of examples. First, let’s get all columns in our df data frame that begin with "new_...". We’ll generate a list of true and false values reflecting if each of the columns begins with “new” and then we’ll pass those true and false values to .loc, which will only give columns for which the result was True. To show what’s going on, we’ll break it into two steps:
print("The list of columns:")
print(df.columns)
print("\n")
print("The list of true and false values:")
print(df.columns.str.startswith("new"))
print("\n")
print("The selection from the data frame:")
df.loc[:, df.columns.str.startswith("new")]The list of columns:
Index(['col0', 'col1', 'col2', 'col3', 'col4', 'col5', 'col6', 'new_column0',
'new_column1', 'new_column2', 'new_column3'],
dtype='object')
The list of true and false values:
[False False False False False False False True True True True]
The selection from the data frame:| new_column0 | new_column1 | new_column2 | new_column3 | |
|---|---|---|---|---|
| a | 0 | 5 | 6 | 0.0 |
| b | 1 | 5 | 6 | 5.0 |
| c | 2 | 5 | 6 | 10.0 |
| d | 3 | 5 | 6 | 15.0 |
| e | 4 | 5 | 6 | 20.0 |
| f | 5 | 5 | 6 | 25.0 |
As well as startswith(), there are other commands like endswith(), contains(), isnumeric(), and islower().
Renaming Columns
There are three easy ways to rename columns, depending on what the context is. The first is to use the dedicated rename() function with an object called a dictionary. Dictionaries in Python consist of curly brackets with comma separated pairs of values where the first values maps into the second value. An example of a dictionary would be {'old_col1': 'new_col1', 'old_col2': 'new_col2'}. Let’s see this in practice (but note that we are not ‘saving’ the resulting data frame, just showing it—to save it, you’d need to add df = to the left-hand side of the code below).
df.rename(columns={"col3": "letters", "col4": "names", "col6": "fruit"})| col0 | col1 | col2 | letters | names | col5 | fruit | new_column0 | new_column1 | new_column2 | new_column3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 | 0.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 | 5.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 | 10.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 | 15.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 | 20.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 | 25.0 |
The second method is for when you want to rename all of the columns. For that you simply set df.columns equal to the new set of columns that you’d like to have. For example, we might want to capitalise the first letter of each column using str.capitalize() and assign that to df.columns.
df.columns = df.columns.str.capitalize()
df| Col0 | Col1 | Col2 | Col3 | Col4 | Col5 | Col6 | New_column0 | New_column1 | New_column2 | New_column3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 | 0.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 | 5.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 | 10.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 | 15.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 | 20.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 | 25.0 |
Finally, we might be interested in just replacing specific parts of column names. In this case, we can use .str.replace(). As an example, let’s add the word "Original" ahead of the original columns:
df.columns.str.replace("Col", "Original_column")Index(['Original_column0', 'Original_column1', 'Original_column2',
'Original_column3', 'Original_column4', 'Original_column5',
'Original_column6', 'New_column0', 'New_column1', 'New_column2',
'New_column3'],
dtype='object')Re-ordering Columns
By default, new columns are added to the right-hand side of the data frame. But you may have reasons to want the columns to appear in a particular order, or perhaps you’d just find it more convenient to have new columns on the left-hand side when there are many columns in a data frame (which happens a lot).
The simplest way to re-order (all) columns is to create a new list of their names with them in the order that you’d like them: but be careful you don’t forget any columns that you’d like to keep!
Let’s see an example with a fresh version of the fake data from earlier. We’ll put all of the odd-numbered columns first, in descending order, then the even similarly.
df = pd.DataFrame(
data=np.reshape(range(36), (6, 6)),
index=["a", "b", "c", "d", "e", "f"],
columns=["col" + str(i) for i in range(6)],
dtype=float,
)
df| col0 | col1 | col2 | col3 | col4 | col5 | |
|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 |
df = df[["col5", "col3", "col1", "col4", "col2", "col0"]]
df| col5 | col3 | col1 | col4 | col2 | col0 | |
|---|---|---|---|---|---|---|
| a | 5.0 | 3.0 | 1.0 | 4.0 | 2.0 | 0.0 |
| b | 11.0 | 9.0 | 7.0 | 10.0 | 8.0 | 6.0 |
| c | 17.0 | 15.0 | 13.0 | 16.0 | 14.0 | 12.0 |
| d | 23.0 | 21.0 | 19.0 | 22.0 | 20.0 | 18.0 |
| e | 29.0 | 27.0 | 25.0 | 28.0 | 26.0 | 24.0 |
| f | 35.0 | 33.0 | 31.0 | 34.0 | 32.0 | 30.0 |
Of course, this is quite tedious if you have lots of columns! There are methods that can help make this easier depending on your context. Perhaps you’d just liked to sort the columns in order? This can be achieved by combining sorted() and the reindex() command (which works for rows or columns) with axis=1, which means the second axis (i.e. columns).
df.reindex(sorted(df.columns), axis=1)| col0 | col1 | col2 | col3 | col4 | col5 | |
|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 |
Review of How to Access Rows, Columns, and Values
With all of these different ways to access values in data frames, it can get confusing. These are the different ways to get the first column of a data frame (when that first column is called column and the data frame is df):
df.columndf["column"]df.loc[:, "column"]df.iloc[:, 0]
Note that : means ‘give me everything’! The ways to access rows are similar (here assuming the first row is called row):
df.loc["row", :]df.iloc[0, :]
And to access the first value (ie the value in first row, first column):
df.column[0]df["column"][0]df.iloc[0, 0]df.loc["row", "column"]
In the above examples, square brackets are instructions about where to grab bits from the data frame. They are a bit like an address system for values within a data frame. Square brackets also denote lists though. So if you want to select multiple columns or rows, you might see syntax like this:
df.loc[["row0", "row1"], ["column0", "column2"]]
which picks out two rows and two columns via the lists ["row0", "row1"] and ["column0", "column2"]. Because there are lists alongside the usual system of selecting values, there are two sets of square brackets.
Tip
If you only want to remember one syntax for accessing rows and columns by name, use the pattern df.loc[["row0", "row1", ...], ["col0", "col1", ...]]. This also works with a single row or a single column (or both).
If you only want to remember one syntax for accessing rows and columns by position, use the pattern df.iloc[[0, 1, ...], [0, 1, ...]]. This also works with a single row or a single column (or both).
Column and Row Exercises
Compare
air_timewitharr_time - dep_time. What do you expect to see? What do you see What do you need to do to fix it?Compare
dep_time,sched_dep_time, anddep_delay. How would you expect those three numbers to be related?Brainstorm as many ways as possible to select
dep_time,dep_delay,arr_time, andarr_delayfromflights.What happens if you include the name of a row or column multiple times when trying to select them?
What does the
.isin()function do in the following?flights.columns.isin(["year", "month", "day", "dep_delay", "arr_delay"])Does the result of running the following code surprise you? How do functions like
str.containsdeal with case by default? How can you change that default?flights.loc[:, flights.columns.str.contains("TIME")](Hint: you can use help even on functions that apply to data frames, eg use
help(flights.columns.str.contains))
Grouping, changing the index, and applying summary statistics
So far you’ve learned about working with rows and columns. pandas gets even more powerful when you add in the ability to work with groups. Creating groups will often also mean a change of index. And because groups tend to imply an aggregation or pooling of data, they often go hand-in-hand with the application of a summary statistic.
The diagram below gives a sense of how these operations can proceed together. Note that the ‘split’ operation is achieved through grouping, while apply produces summary statistics. At the end, you get a data frame with a new index (one entry per group) in what is shown as the ‘combine’ step.
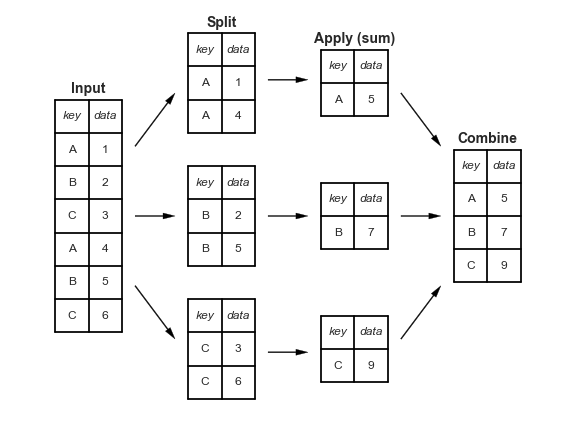
Grouping and Aggregating
Let’s take a look at creating a group using the .groupby() function followed by selecting a column and applying a summary statistic via an aggregation. Note that aggregation, via .agg(), always produces a new index because we have collapsed information down to the group-level (and the new index is made of those levels).
The key point to remember is: use .agg() with .groupby() when you want your groups to become the new index.
(flights.groupby("month")[["dep_delay"]].mean())| dep_delay | |
|---|---|
| month | |
| 1 | 10.036665 |
| 2 | 10.816843 |
| 3 | 13.227076 |
| 4 | 13.938038 |
| 5 | 12.986859 |
| 6 | 20.846332 |
| 7 | 21.727787 |
| 8 | 12.611040 |
| 9 | 6.722476 |
| 10 | 6.243988 |
| 11 | 5.435362 |
| 12 | 16.576688 |
This now represents the mean departure delay by month. Notice that our index has changed! We now have month where we original had an index that was just the row number. The index plays an important role in grouping operations because it keeps track of the groups you have in the rest of your data frame.
Often, you might want to do multiple summary operations in one go. The most comprehensive syntax for this is via .agg(). We can reproduce what we did above using .agg():
(flights.groupby("month")[["dep_delay"]].agg("mean"))| dep_delay | |
|---|---|
| month | |
| 1 | 10.036665 |
| 2 | 10.816843 |
| 3 | 13.227076 |
| 4 | 13.938038 |
| 5 | 12.986859 |
| 6 | 20.846332 |
| 7 | 21.727787 |
| 8 | 12.611040 |
| 9 | 6.722476 |
| 10 | 6.243988 |
| 11 | 5.435362 |
| 12 | 16.576688 |
where you pass in whatever aggregation you want. Some common options are in the table below:
| Aggregation | Description |
|---|---|
count() |
Number of items |
first(), last() |
First and last item |
mean(), median() |
Mean and median |
min(), max() |
Minimum and maximum |
std(), var() |
Standard deviation and variance |
mad() |
Mean absolute deviation |
prod() |
Product of all items |
sum() |
Sum of all items |
value_counts() |
Counts of unique values |
For doing multiple aggregations on multiple columns with new names for the output variables, the syntax becomes
(
flights.groupby(["month"]).agg(
mean_delay=("dep_delay", "mean"),
count_flights=("dep_delay", "count"),
)
)| mean_delay | count_flights | |
|---|---|---|
| month | ||
| 1 | 10.036665 | 26483 |
| 2 | 10.816843 | 23690 |
| 3 | 13.227076 | 27973 |
| 4 | 13.938038 | 27662 |
| 5 | 12.986859 | 28233 |
| 6 | 20.846332 | 27234 |
| 7 | 21.727787 | 28485 |
| 8 | 12.611040 | 28841 |
| 9 | 6.722476 | 27122 |
| 10 | 6.243988 | 28653 |
| 11 | 5.435362 | 27035 |
| 12 | 16.576688 | 27110 |
Means and counts can get you a surprisingly long way in data science!
Grouping by multiple variables
This is as simple as passing .groupby() a list representing multiple columns instead of a string representing a single column.
month_year_delay = flights.groupby(["month", "year"]).agg(
mean_delay=("dep_delay", "mean"),
count_flights=("dep_delay", "count"),
)
month_year_delay| mean_delay | count_flights | ||
|---|---|---|---|
| month | year | ||
| 1 | 2013 | 10.036665 | 26483 |
| 2 | 2013 | 10.816843 | 23690 |
| 3 | 2013 | 13.227076 | 27973 |
| 4 | 2013 | 13.938038 | 27662 |
| 5 | 2013 | 12.986859 | 28233 |
| 6 | 2013 | 20.846332 | 27234 |
| 7 | 2013 | 21.727787 | 28485 |
| 8 | 2013 | 12.611040 | 28841 |
| 9 | 2013 | 6.722476 | 27122 |
| 10 | 2013 | 6.243988 | 28653 |
| 11 | 2013 | 5.435362 | 27035 |
| 12 | 2013 | 16.576688 | 27110 |
You might have noticed that this time we have a multi-index (that is, an index with more than one column). That’s because we asked for something with multiple groups, and the index tracks what’s going on within each group: so we need more than one dimension of index to do this efficiently.
If you ever want to go back to an index that is just the position, try reset_index()
month_year_delay.reset_index()| month | year | mean_delay | count_flights | |
|---|---|---|---|---|
| 0 | 1 | 2013 | 10.036665 | 26483 |
| 1 | 2 | 2013 | 10.816843 | 23690 |
| 2 | 3 | 2013 | 13.227076 | 27973 |
| 3 | 4 | 2013 | 13.938038 | 27662 |
| 4 | 5 | 2013 | 12.986859 | 28233 |
| 5 | 6 | 2013 | 20.846332 | 27234 |
| 6 | 7 | 2013 | 21.727787 | 28485 |
| 7 | 8 | 2013 | 12.611040 | 28841 |
| 8 | 9 | 2013 | 6.722476 | 27122 |
| 9 | 10 | 2013 | 6.243988 | 28653 |
| 10 | 11 | 2013 | 5.435362 | 27035 |
| 11 | 12 | 2013 | 16.576688 | 27110 |
Perhaps you only want to remove one layer of the index though. This can be achieved by passing the position of the index you’d like to remove: for example, to only change the year index to a column, we would use:
month_year_delay.reset_index(1)| year | mean_delay | count_flights | |
|---|---|---|---|
| month | |||
| 1 | 2013 | 10.036665 | 26483 |
| 2 | 2013 | 10.816843 | 23690 |
| 3 | 2013 | 13.227076 | 27973 |
| 4 | 2013 | 13.938038 | 27662 |
| 5 | 2013 | 12.986859 | 28233 |
| 6 | 2013 | 20.846332 | 27234 |
| 7 | 2013 | 21.727787 | 28485 |
| 8 | 2013 | 12.611040 | 28841 |
| 9 | 2013 | 6.722476 | 27122 |
| 10 | 2013 | 6.243988 | 28653 |
| 11 | 2013 | 5.435362 | 27035 |
| 12 | 2013 | 16.576688 | 27110 |
Finally, you can do more complicated re-arrangements of the index with an operation called unstack, which pivots the chosen index variable to be a column variable instead (introducing a multi column level structure). It’s usually best to avoid this.
Grouping and Transforming
You may not always want to change the index to reflect new groups when performing computations at the group level.
The key point to remember is: use .transform() with .groupby() when you want to perform computations on your groups but you want to go back to the original index.
Let’s say we wanted to express the arrival delay, "arr_del", of each flight as a fraction of the worst arrival delay in each month.
flights["max_delay_month"] = flights.groupby("month")["arr_delay"].transform("max")
flights["delay_frac_of_max"] = flights["arr_delay"] / flights["max_delay_month"]
flights[
["year", "month", "day", "arr_delay", "max_delay_month", "delay_frac_of_max"]
].head()| year | month | day | arr_delay | max_delay_month | delay_frac_of_max | |
|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 11.0 | 1272.0 | 0.008648 |
| 1 | 2013 | 1 | 1 | 20.0 | 1272.0 | 0.015723 |
| 2 | 2013 | 1 | 1 | 33.0 | 1272.0 | 0.025943 |
| 3 | 2013 | 1 | 1 | -18.0 | 1272.0 | -0.014151 |
| 4 | 2013 | 1 | 1 | -25.0 | 1272.0 | -0.019654 |
Note that the first few entries of "max_delay_month" are all the same because the month is the same for those entries, but the delay fraction changes with each row.
Groupby Exercises
Which carrier has the worst delays? Challenge: can you disentangle the effects of bad airports vs. bad carriers? Why/why not? (Hint: think about
flights.groupby(["carrier", "dest"]).count())Find the most delayed flight to each destination.
How do delays vary over the course of the day?